
Part 1: The Spark
I don’t remember exact details of that day. Maybe I was staring at my ceiling, scrolling LinkedIn, refreshing JobStreet every five minutes? Doesn’t matter. I was—and still am—in that suspended state of having lost a job. What I DO remember vividly: I wanted to go crazy with my AWS free tier. So I think I did just that—roaming around the AWS dashboard, exploring services, when I saw it.
AWS Bedrock
So I was thinking, what if I could paste my Spotify playlist URL and have an AI analyze my music taste, then roast it? (I made it up because i dont remember how it this idea came) The funny thing is next day is 31 August 2025 so I was like
alright lets make the bedrock cooked my playlist but in mamak malaysian style (cringe, but you get what I wanted to say)
That’s how it started. Spotify API + AWS Bedrock + Malaysian cultural data = an AI that roasts playlists with authentic Malaysian humor.
Part 2: Teaching AI How Malaysians Actually Talk (The Grok Phase)
AI sure is smart, but it doesn’t naturally speak Malaysian English. I needed to teach it cultural context like slang, food references, local lifestyle.
So I asked Grok (the Twitter AI) to analyze how Malaysians post on social media. Like what’s the pattern? I picked Grok simply because Grok easily access tweets (Idc man i still called them Twitter until today)
What Grok got:
-
Sentence particles are everything: “lah” for emphasis, “wor” for questions, “mah” for explanations
- Example: “Why your playlist so mainstream wor?”
- Without “wor”: “Why your playlist so mainstream?” → sounds wrong
-
Cultural references carry the joke:
- Food: roti canai, nasi lemak, teh tarik, mamak
- Places: KL traffic, Grab rides, pasar malam
- Lifestyle: office work, Friday night plans, “aiyah” moments
-
The roast angles:
- Mainstream: “All Top 40 - your taste flatter than roti canai!”
- No local artists: “Zero Malaysian songs - you forgot you’re Malaysian ah?”
- Same artists: “Only listening to 3 artists - very satu hal lah!”
The prompt engineering:
|
|
Part 3: The Statefulness Epiphany
I thought I understood data storage because I used localStorage and Vue’s ref(). Then I learned:
servers don’t remember anything
There was this weird issue I faced where I could roast a playlist but when I checked the public feed, same playlist kept showing up again.
I was thinking: Wait, didn’t I already roast this playlist? Why is it showing up again?
So I found that my POST worked (saves roast) but GET kept showing duplicates because:
AWS Lambda is STATELESS each function call might run on a different server instance
|
|
The fix:
|
|
Again we have to remmember that backend doesn’t remember anything.
Databases remember everything.
Part 4: Architecture - How This Thing Actually Connects
|
|
What this actually means:
- Frontend: Just renders stuff, handles user interaction
- API Gateway: The bouncer that routes requests to Lambda
- DynamoDB: Rate limiting - prevents spam (10 requests/day per IP)
- RDS MySQL: Stores roasts, remembers what we already roasted
Part 5: The Race Condition Problem (Or How I Documented a Bug I Haven’t Fixed Yet and never fix it)
I didn’t want people spamming my app. Imagine someone testing their 50 different playlists just for fun. So I set up rate limiting: 10 requests per day per IP address.
The idea was simple enough. Check how many times this IP has requested in the last 24 hours. If it’s less than 10, let them through. If not, block them.
What could go wrong? But my code is a problem and thankfully im not influencer enough to get this problem ! :D
What I saw: Rate limiting sometimes allows 11 or 12 requests instead of 10
What I actually coded:
|
|
What actually happens with concurrent requests:
|
|
Status: This is a KNOWN BUG in production. I documented it as a TODO but haven’t fixed it yet and I don’t want to fix it.
How This Could Be Fixed (Requires Data Model Redesign):
The documented solution would require changing from my current “one-item-per-request” model to a “counter-per-IP” model:
|
|
This is more than just adding a ConditionExpression - it requires:
- Schema migration (item-per-request → counter-per-IP)
- Handling counter resets (24-hour windows)
- TTL strategy adjustment
Why my current “one-item-per-request” model can’t easily use atomic operations:
- Query counts items (not atomic)
- Put creates new items (not updating a counter)
- No single field to conditionally check
Why I Haven’t Fixed It Yet:
- This project is just for fun
- I dont have mood to do it
- I have backlog anime/movies/games to finish
- Looking for job aggressively
All these are majority from AI suggestions but yeah I kind of get it how i should do it,
Part 7: People Actually Tried It
After deploying the app, I posted it on Instagram stories. Just a quick “built this thing that roasts your Spotify playlist” with a link. Thought maybe a few friends would try it for the memes. They don’t just scrolling past, but actually pasting their Spotify URLs !!!!!!!!!!
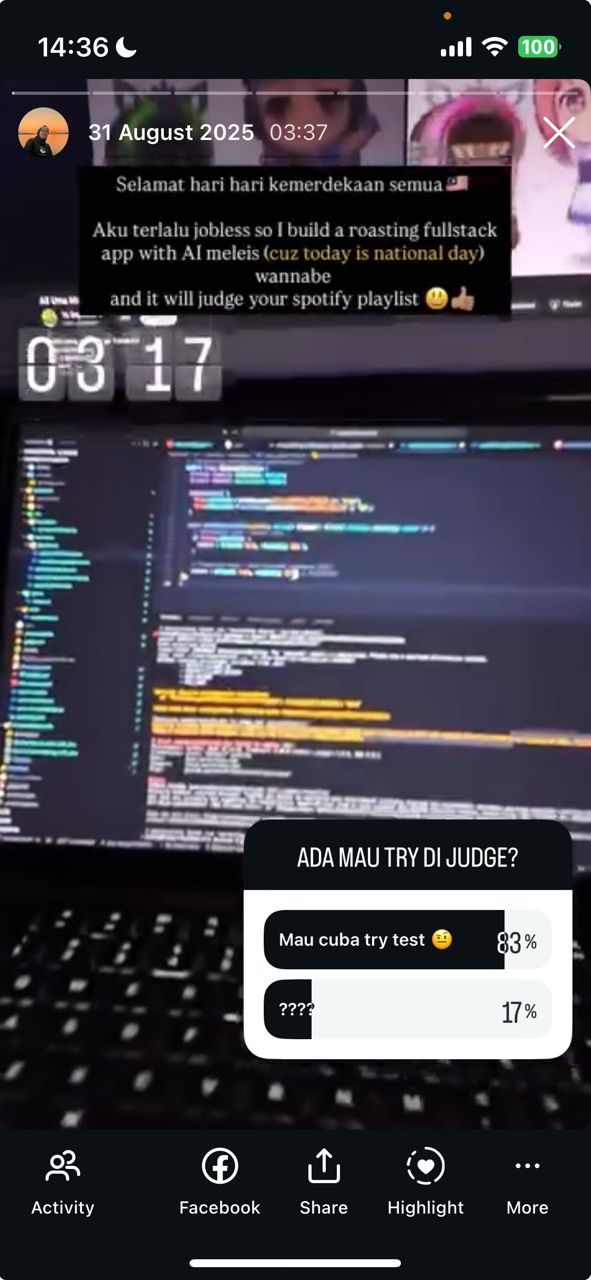
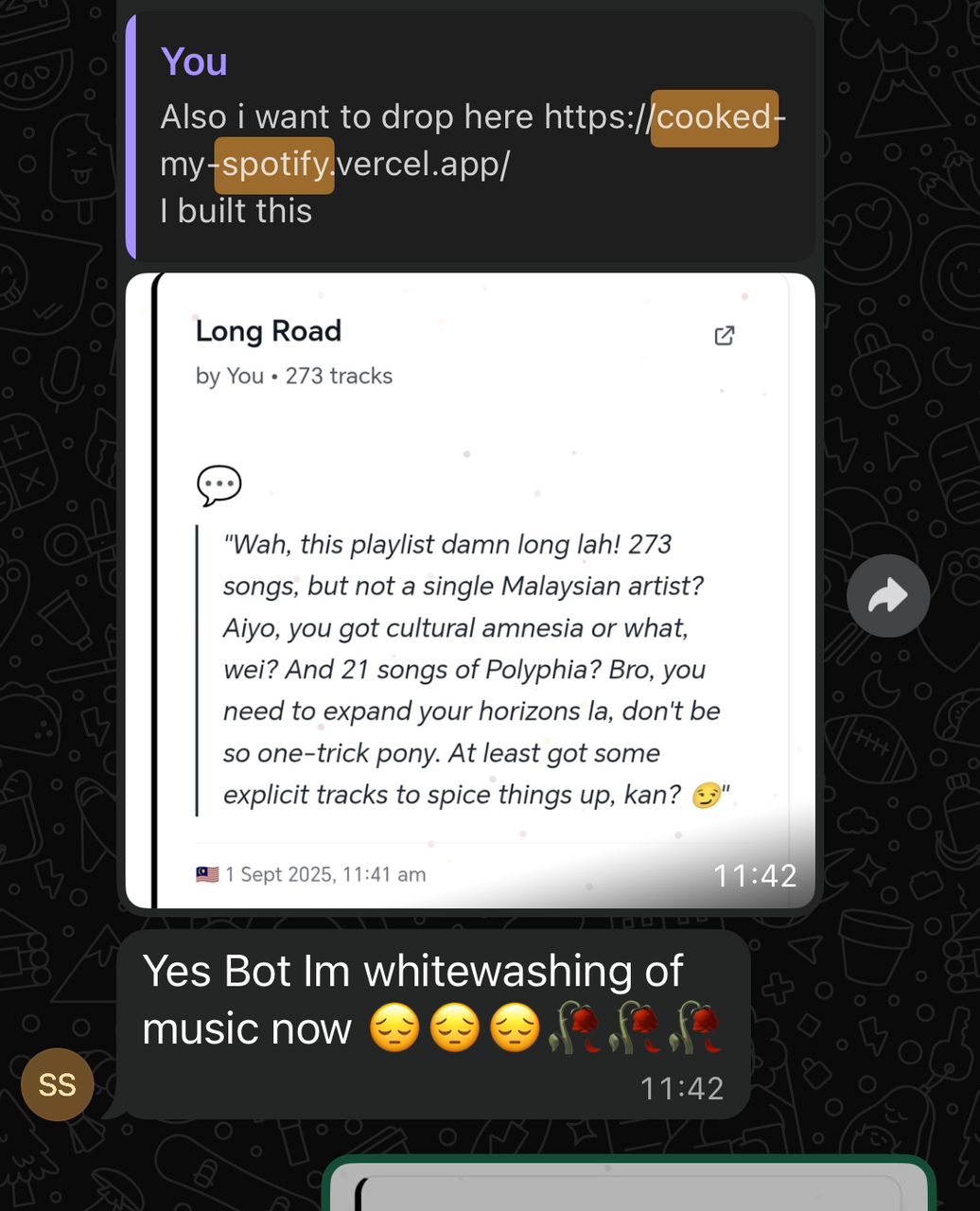
Real users, not just me testing my own code. That’s what jobless projects don’t usually get. Its fun to see the results tbh
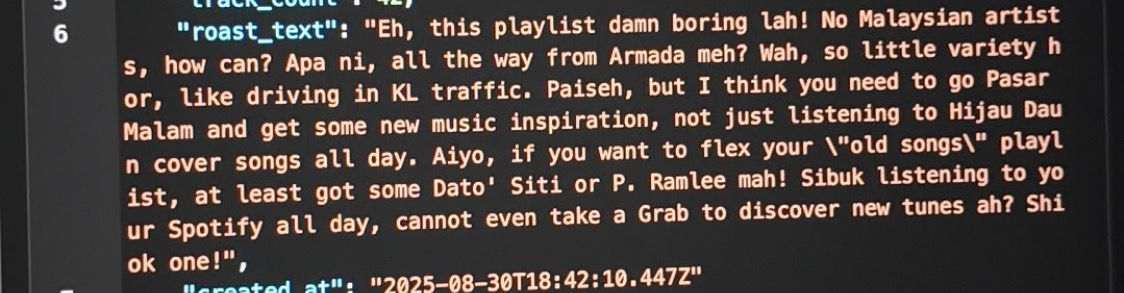
Here are some photos when i tried testing on Bruno too before deploy, honestly its very fun thing to do.

Part 8: What I Haven’t Fixed Yet
Why do you have to know? Real projects aren’t perfect. Honest about what works, what’s broken, and what you’d do differently. That’s more valuable than fairy tales about flawless code.
Known Issues
Issue 1: Rate Limiting Race Condition ❌
Status: Known bug, documented as TODO, NOT fixed
The Problem:
- Current code uses check-then-increment pattern (yapped about it at Part 5)
- Two concurrent requests can both pass check (both see count=9)
- Result: User makes 11 requests instead of 10 limit
Why I Haven’t Fixed It:
- I don’t want to
- Not pay my bills
Future Improvements
Improvement 1: Pagination Performance ⚠️
This thing sure it works, could be better at scale
Current Implementation: LIMIT/OFFSET approach
- Works fine for <10,000 records
- Gets slow at page 100+ (OFFSET 1000+)
Why It’s Fine Now:
- Public feed has ~5+ roasts
- Nobody clicking past pagination
- Fix not needed until dataset grows
Improvement 2: Duplicate Detection Accuracy ⚠️
Status: Works for most cases
Current Implementation: Checks by playlist_spotify_id
- Prevents re-roasting same playlist
- Works perfectly for renamed playlists
Limitation: Same content, different playlist = new roast
- Example: 50 identical songs, different names
- Rare edge case
Why It’s Acceptable Now:
- Playlist ID is unique and permanent
- Most users won’t have duplicate content across playlists
Final Thoughts
Did this get me a job? I wish man lol. But hey on the bright side, joblessness built something good xuz I am having time to actually finish a project for once
Did this get me something better? Yeah - proof that I can:
- Build full-stack from scratch (not just frontend anymore)
- Integrate AI with actual business value
- Ship production-ready code (not just another abandoned project)
- Build something people actually use and share
What’s next? Maybe I’ll add user accounts so people can save their roasts. Maybe I’ll add comparison mode to roast two playlists at once. Or maybe I’ll just apply to jobs again tomorrow.