
Introduction
Yooooooooo I finally have a non-abandoned personal project that I actually completed! 
People have no idea how many damn-heck-tons of personal projects I’ve kickstarted but after months (sometimes years) I just delete the repo from my GitHub because I… forgot why I created it and what my end goal was lol.
This time I finally did something meaningful! I called it Smart Task Manager because I didn’t want it to be too cliché with “To Do Task” so I added a small AI integration to make it slightly more interesting than the usual todo app.
Why this project mattered to me: I’ve always been the “frontend person” in conversations, but I wanted to understand the full picture. Every time backend devs talked about scaling, databases, or deployment, I felt like I was missing half the conversation. This project was my attempt to speak their language.
I started this project because I wanted to try my first ever hands-on experience creating APIs with AWS (this particular reason I also put in Tech Hot Takes category as wel).
Actually was pretty exciting since all this time I was scared of creating an AWS account because of potential bills, so I spent SO much time researching beforehand haha so without further ado, let’s talk about it! :D
Github repo can be found here btw
Tech Stack & Decision Reasoning
Frontend:
- Nuxt.js + Vue 3 (familiar territory, but wanted to focus on backend learning)
- Tailwind CSS + Shadcn Vue (ngl my first ever try to use Shadcn Vue usually I use this for react)
- TypeScript (superduper rusty already man I have been using JS only all this time mostly for work)
Backend:
- Node.js + AWS Lambda (let alone Node, serverless was completely new)
- AWS API Gateway (wanted to learn AWS properly)
- Serverless Framework (nope never try this either)
Database:
- Supabase (have this account for long time but never actually use it lol)
AI:
- Google Gemini API (apparently there is free tier yay! i can play around with RM0)
The Architecture I Built
|
|
Honestly, the whole experience was fun? My frontend brain trying to understand backend concepts? Can I get through this…
Part 1: Fundamental Backend Mindset Shifts
Request/Response Lifecycle Thinking
Coming from frontend, the biggest mental shift was understanding that backend thinks in request → process → response cycles not just that instead of creating an app it is more like creating a system plus not continuous user interactions:
Frontend Brain: “User clicks button → component state updates → UI reacts → user sees change”
Backend Brain: “Request arrives → validate → process → store → respond → forget everything”
What Are My Key(s) Take Away:
- Each Lambda function (image above) is stateless - they’re like goldfish or Dory(?) with fresh memory every time
- Database is the source of truth, not component state, the usual
ref()means nothing here - Error handling must be bulletproof because there’s no user to click “try again”
- Validation happens server-side - never trust frontend input (sorry frontend me lol)
- Less intimidating as I go - I get used or should I say being pampered in frontend with Instant gratification? because I see changes immediately, but for backend its more like delayed gratification as I need to build infrastructure first, see results later
The Stateless Architecture I Learned
I thought I understood data storage because I used localStorage and Vue’s ref(). Then I learned:
servers don’t remember anything
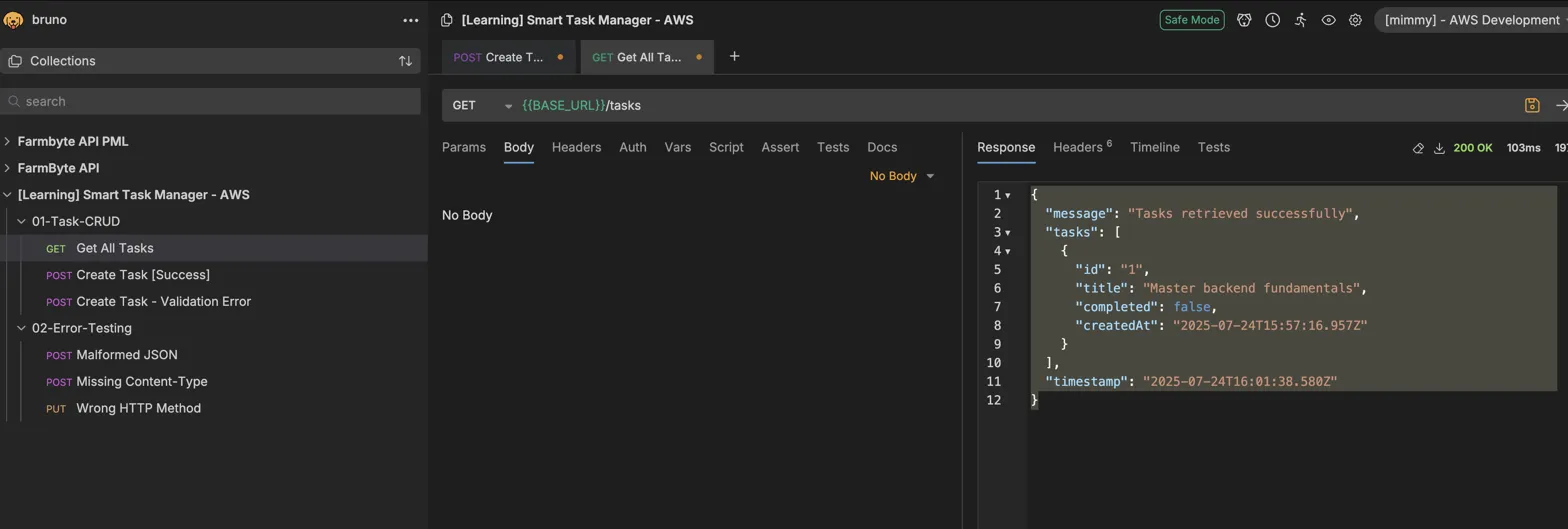
There is another weird issue that I faced where I able to created but when I request GET all task its always
|
|
I was thinking, isn’t supposed to be, I able to see my second task that I created in the list too? Why I am not seeing it? Why only 1?
So I found that my
POST works (creates task) but GET doesn’t show it because:
AWS Lambda is STATELESS - Each function call might run on a different server instance
|
|
🍳 Analogy of this:
Frontend (Like a Coffee Shop):
- I sit at ONE table with ONE barista
- My order stays on your table until I leave
- Same barista remembers what I ordered all day
Backend Lambda (Like Uber Eats):
- Each order goes to ANY available kitchen
- Kitchen A makes my burger → stores it in Kitchen A’s memory
- Kitchen B gets my drink order → has NO IDEA about the burger
- Kitchens shut down when not busy → burger memory GONE
Now now now, suddenly databases weren’t just “where my store stuff” huh? They became the only way different parts of my system can have a conversation.
It acts like this cus I haven’t set up database properly.
Database as the Single Source of Truth
Frontend thinking: “I’ll just keep this in a variable”
Backend thinking: “Where does this live when the server restarts?”
Key insights:
- Data persistence is forever - information survives page refreshes, deployments, and server meltdowns
- Query patterns change everything -
.eq('task_id', task_id).single()hits different than component props - Adding columns is easy (in my case just slap an
ai_analysisJSONB field on there) - Data relationships matter - foreign keys aren’t just suggestions, they’re kinda like family bonds
Part 2: Real-World Integration Challenges
External API Integration Part
Integrating Google Gemini kinda messy to me (skill issue lol):
Root Causes:
- Model names change (
gemini-pro→gemini-1.5-flash) - gave me SO many errors - Token limits matter - had to bump from 300 to 800 tokens for thinking mode
- Error handling is life or death - API failures can’t crash my app if I were the real user idc if my api having a bad day? shouldn’t make the whole app crash
- Rate limits exist - APIs will literally tell you to chill out and come back later
- Response times vary wildly - sometimes 200ms, sometimes 5 seconds
- Cost consciousness is real - every API call costs actual money
Backend Error Handling Strategy
Unlike frontend where errors show pretty toast notifications, backend errors must be logged and logged and logggg:
Frontend errors: “Oopsie, something wrong! 🤷♀️”
Backend errors: “Database connection failed, 500 users affected, your system bad bro”
What I Learned:
- Try-catch blocks around EVERYTHING - especially external calls
- Detailed logging for debugging - future you will thank present you (thanks AI helped to write the log so detailed)
- User-friendly vs technical errors - users get “Try again”, logs get stack traces
- Fail fast and loud - validate input before expensive operations
I asked Claude to help me console.log literally everything for AI Analysis debugging:
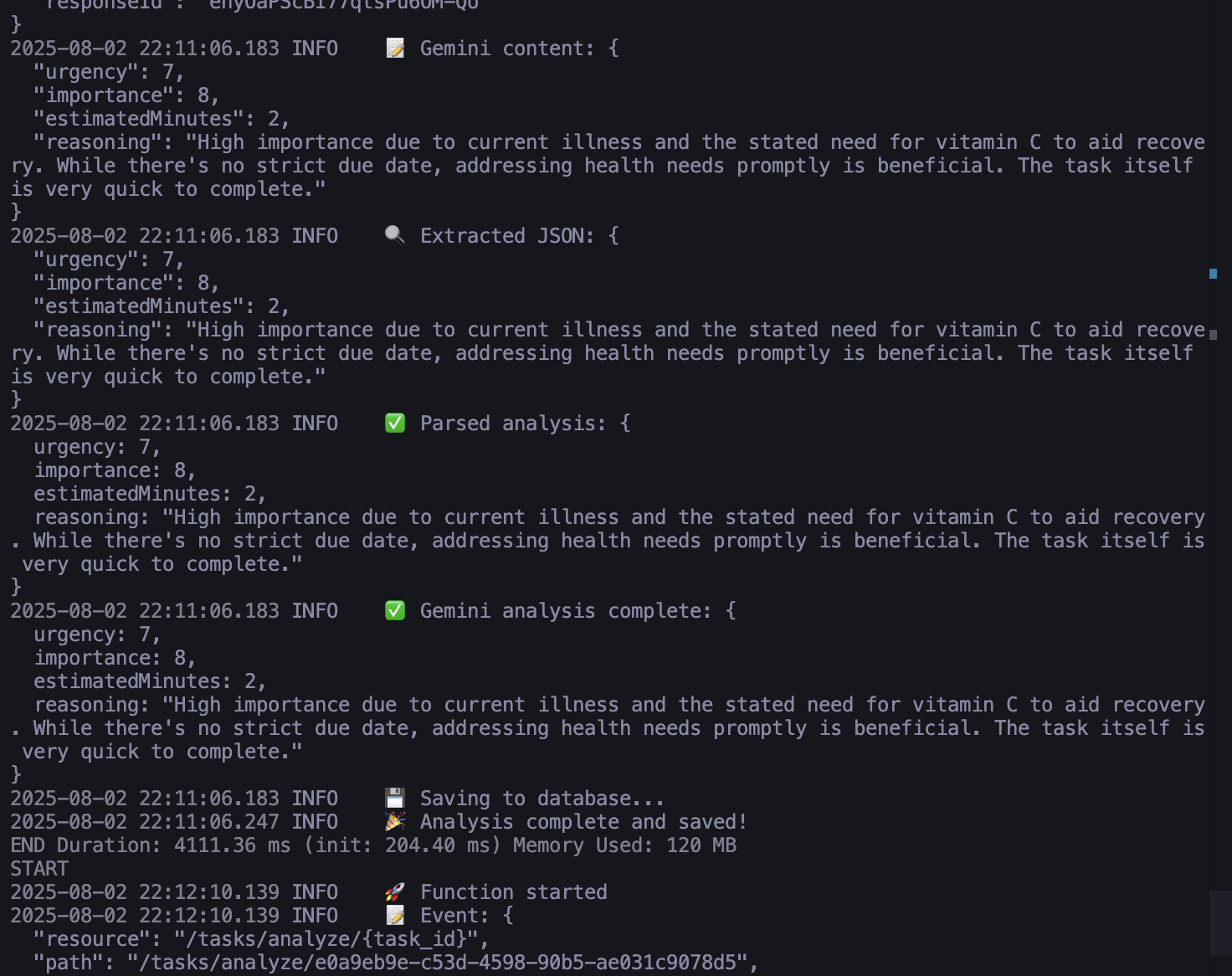
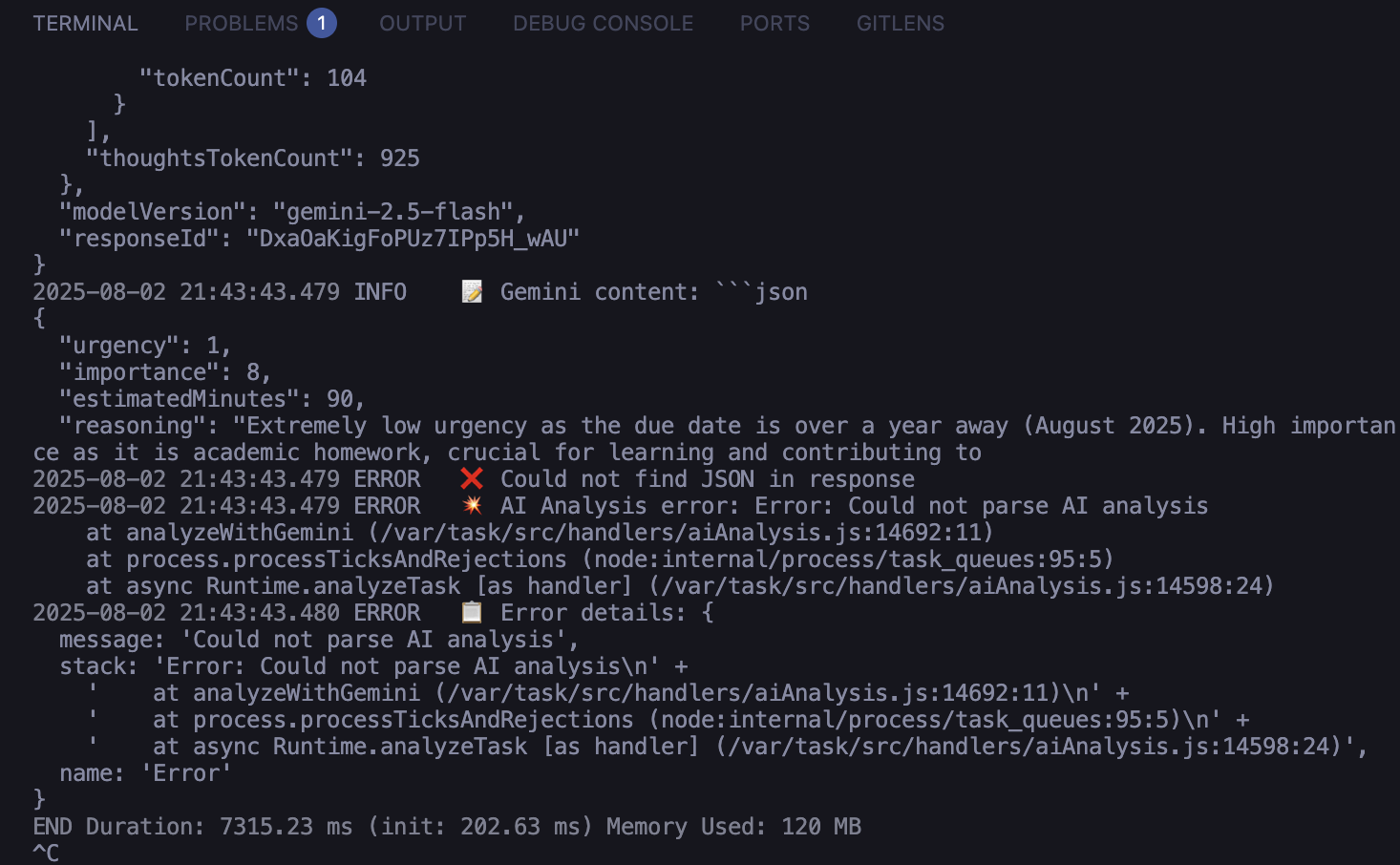
For this part my internal monologue became:
“Did my function even run? wtf are my request even atp? Why is the database angry me man? Is the API key working? PLEASE JUST TELL ME SOMETHING USEFUL.”
Serverless Development Workflow (aka “Deploy to Find Out”)
Learning AWS Lambda deployment cycles was… an experience:
- Deploy to test everything - no
localhost:3000equivalent - CloudWatch logs became my new browser DevTools -
console.logis my bestie atp serverless logs --tailfor real-time debugging too like watching terminal shitposting haha- Cold starts - first request after deployment is slower..
- Everything takes longer - frontend: save file → see changes, backend: save file → deploy → pray → debug
Part 3: Design Patterns I Accidentally Discovered
Backend Patterns I Built
Repository Pattern
|
|
Turns out I was building repositories without knowing it! If I have to make myself understand better it’s like organizing my closet. I have a “clothes drawer” (useApi) and a “weaboo shirts section” (useTasks).
One handles the storage mechanics, the other knows what “weab casual” means or should I say anime otaku event I pull this section/drawer haha.
Data Transfer Object (DTO) Pattern
Man let me tell you about the day I realized my “simple” task manager was actually a data transformation nightmare.
Here’s what my code looked like before DTOs:
|
|
See the problem? I had three different ways to transform the same API response. When the backend changed modified_at to updated_at, I had to hunt through my entire codebase haha
Enter the DTO: Our Data’s Border Control
DTO stands for Data Transfer Object, the job is basically a place where my frontend negotiates with the backend’s naming preferences.
Here’s my actual implementation:
|
|
Why This Actually Matters?
-
Type Safety as Documentation: When I have a single transformation function, it becomes living documentation of my API contract. Every field mapping is explicit and testable.
-
Change Resistance: Lets say BE changed
ai_analysistoaiInsights? One line change in DTO instead of hunting through tons components. -
Data Validation & Sanitization - DTO becomes the perfect place to handle edge cases:
- Missing fields get default values
- String dates become actual Date objects
- Optional fields get properly typed as
undefinedinstead ofnull
So essentially it’s not just about naming conventions ! DTOs will solve this with consistent transformation rules.
Facade Pattern
For this I like to think it this way.. Like, going to a hospital, I don’t want to navigate to the lab, find the radiologist, locate the pharmacy, and handle insurance by myself. I talk to the receptionist (facade) who handles all that complexity.
|
|
Event-Driven Architecture Implementation
The AI analysis feature taught me asynchronous processing:
- Don’t block users - save task immediately, analyze later when user wants it
- On-demand processing - only hit expensive APIs when user clicks “analyze”
- Cache everything expensive - store AI results, don’t pay twice
- Graceful degradation - app works even if AI is having existential crisis
- Status tracking - users need to know “is this thing thinking or broken?”
Part 4: My Struggle Stories
CORS Lah Bro What Else?
Even as FE CORS issue is a common problem, I sometimes had this issues but usually our BE devs will always help to solve it.
Now at this case, I need to solve it by myself not as FE devs but as Fullstack dev !
Before I started to dig this issue to make myself understand what is going on ?
Well its simple, it is a web security feature that browsers enforce.
As API’s usually acts as a Waiter in common restaurant analogy for CORS let’s think it this way
|
|
What Happens Technically
When my frontend tries to make certain requests (POST, PUT, DELETE with custom headers):
- Step 1: Browser sends OPTIONS request (preflight)
|
|
- Step 2: Backend responds with permissions
|
|
- Step 3: Browser sends actual request
|
|
So this is where I had to create options handler because without it, it is like
|
|
By having it, it will handle it like
|
|
AWS CLI Issue
At first I wasn’t really clear what is this about actually? So I want to understand more so I wanted AI explained to me and the analogy that really makes sense to me is this:
|
|
It was a fast fix atually but my goal is I wanted to understand this tool why this is useful and yeah I like how AI explained to me better why this tool is convenient for me.
AWS Deployment Complexity
AWS felt like trying to order coffee in Kelate(Kelantan) slang where one wrong word could get you teh tarik instead of kopi-o. Coming from frontend where I just run npm run dev and boom, localhost just happen if I set up correctly right? Scaffolding is pretty much ez too with one command, but bro AWS was like:
“Oh, you want to deploy? First create an IAM user, then configure CLI credentials, then understand regions, then learn YAML syntax, then understand Lambda execution roles, then pray your serverless.yml is correct, then debug why your Lambda function crashed cuz it sucks lol”
Being a cheapskate on AWS Free Tier actually taught me resource awareness
- Avoid duplicate API calls - check if analysis exists before hitting Gemini
- Monitor token usage - even I got Gemini free tier tokens aren precious!
- Optimize database queries - don’t fetch entire table for one row
- Cache expensive operations - save AI responses
- Set billing alerts - Before I begin my project this I set this first and AWS gave me 20 bucks haha
Free tier limitations forced me to write better code. Constraints breed creativity! ;D
The “Missing Authentication Token” Rabbit Hole
Mistake that took me for hours:
|
|
AWS returned Missing Authentication Token and I’m sitting there like
“bruh, I never even SET UP authentication, what token?!”
Turns out mixing http and httpApi events creates completely different AWS services. Dia macam ko nasi lemak dari satu stall lepastu try collect it from ANOTHER stall 🤦♂️
So I stick with http as I want to have better CORS control. I could be wrong or there should be a better way on this but hey it works.
The Gemini API Evolution
Embarassingly I started confidently with:
|
|
Google Gemini: “gemini-pro is not found”
Me: “??? It is in the documentation examples”
Turns out gemini-pro got deprecated. Had to update to gemini-2.5-flash. External APIs evolve without asking your permission so we stay update folks. Read docs properly and based on what version you using, dont be like me haha.
The Token Limit Plot Twist
Finally got Gemini working atp, API returns 200 success, but response is:
|
|
The model was literally thinking so hard (299 tokens of internal reasoning) that it ran out of tokens before giving me an actual answer. Essentially it’s like asking someone a question and they spend so much time thinking they forget to respond.
So I had to increase maxOutputTokens from 300 to 1000.
Backend Debugging: The CloudWatch! Or Console.log() spam!
Frontend debugging:
Open browser DevTools, see error, fix it. (not this straight forward but you get my point)
Backend debugging:
- Deploy code
- Make API request
- Get generic error
- Check CloudWatch logs
- Find actual error buried in JSON
- Fix code
- Deploy again
- Repeat
Learning serverless logs --tail was a game changer too. Real-time logs made me feel like a hacker watching Matrix code scroll by on Warp CLI hehe
What’s Next
Definitely want to explore more backend technologies. Maybe try Go or HTMX next time? Or dive deeper into AWS services more by finishing my unclaim rewards.
For this experience my mindset shift from “user interactions” to “data transformations” was the hardest part, but also the most valuable. Backend isn’t about what users see I think, it’s about what systems do when no one is watching.
This also makes me realized even more, coming from FE lah, where I can see immediate visual feedback, backend felt like coding blindfolded. The imposter syndrome even hits me so hard:
“Real backend developers probably don’t need this many console.logs”
“I’m using AI to help with syntax, am I even coding?”
“Why does everyone else make this look easy?”
But then I realized:
Thinking through problems matters more than syntax memory. Understanding stateless architecture, designing APIs, handling errors gracefully. I personally think these are the real skills.
It was fun till the end, there are more issues but I took some that I remember the most and I also don’t want to post so long.
My FE brain usually:
“User clicks button → immediate visual feedback”
But BE brain I think I have to twist bit like:
“Request comes in → validate input → check database → call external API → handle errors → save results → return response”
The hardest part wasn’t learning syntax, it was rewiring my brain as feels this bit of mind-boggling.
Anyway, I hope I can stay consistent to learn more!